
 February 13, 2026
February 13, 2026  8 Min
8 Min  No Comment
No Comment 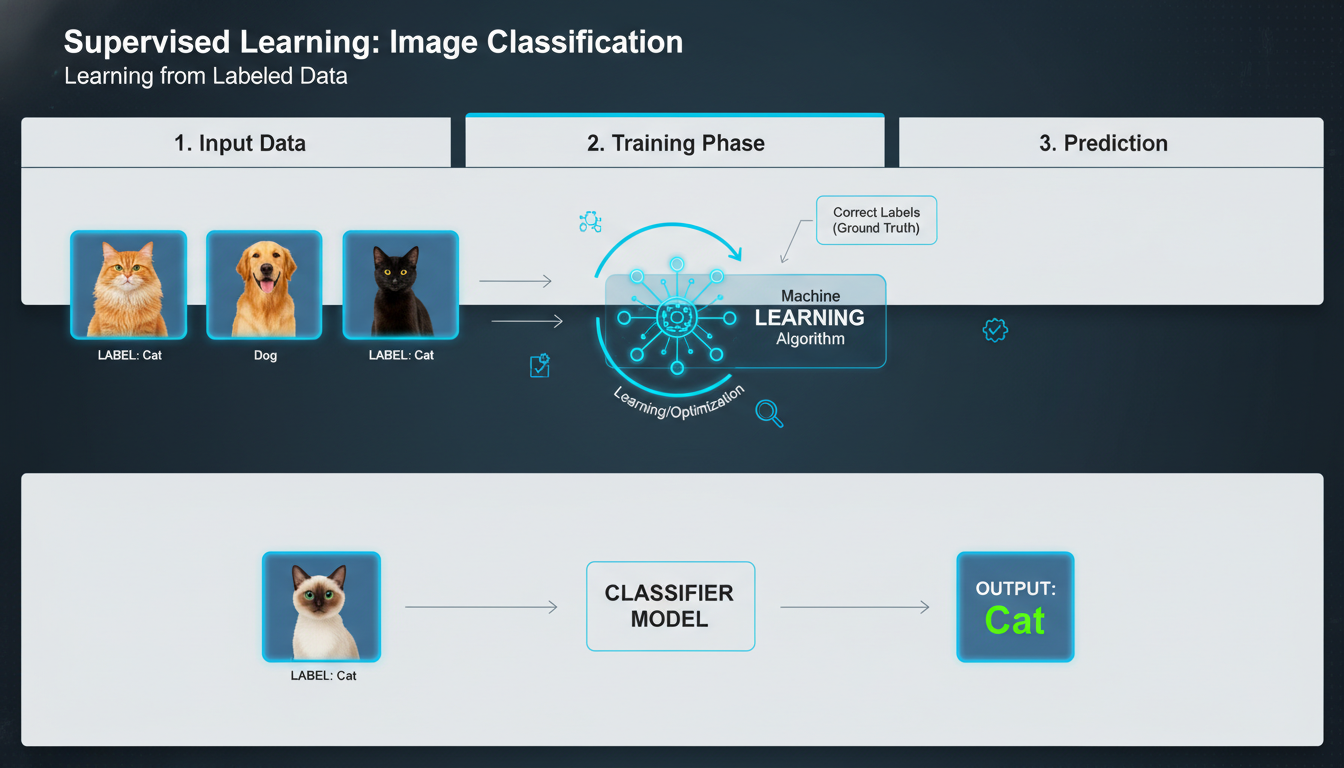
Delving into the world of Machine Learning Algorithms: The Brains Behind Artificial Intelligence, there’s a comforting truth: these algorithms are surprisingly approachable, even if they sound fancy. When you break it down, machine learning (ML) is like teaching a computer to spot patterns and make decisions—not just follow hardcoded instructions. It’s that spark of flexibility, of “aha—that’s clever,” that makes ML the engine driving AI. And yes, it’s a bit messy, a bit unpredictable—just like real brains.
In real life, companies don’t always commission massive data science projects—they might sketch out prototypes on a whiteboard or tinker with small datasets. These efforts evolve, sometimes ironically, into business-changing tools. That near-mythical journey—from scribbles to mind-bending recommendations—shows how machine learning algorithms quietly become the brains behind AI. Let’s explore that story together, with a pinch of human uncertainty and a touch of deliberate chaos.
Understanding Core Types of Machine Learning Algorithms
Machine learning has many flavors. Each serves a different purpose, and knowing when to use what is like having the right tool for the job.
Supervised Learning: Teaching with Examples
Supervised learning is exactly what it sounds like: teaching a model with labeled data. You tell it, “Here’s a cat, here’s not-a-cat,” and after many examples, it generalizes.
– Think image recognition, spam detection, or predicting housing prices. The algorithm learns to map inputs to outputs by minimizing an error function (mean squared error, cross-entropy, etc.).
– It’s effective and intuitive, but it depends heavily on quality labels. And guess what? Labeling is one of those annoyingly tedious human tasks that rarely gets simpler.
Unsupervised Learning: Letting Patterns Speak
On the flip side, unsupervised learning hands unlabeled data to an algorithm and says, “Go sort it.”
– Clustering (like K-means) groups similar items together; dimensionality reduction (such as PCA or t-SNE) compresses data for visualization or faster processing.
– There’s something delightfully exploratory about this: no teacher, just discovery. On the other hand, interpreting the results can feel like staring at cloud shapes—subjective and murky.
Reinforcement Learning: Reward-driven Learning
Reinforcement learning (RL) is its own genre: an agent, an environment, actions, and rewards. Think training a robot or AI to play a game through trial and error.
– The agent explores and gradually optimizes its strategy based on feedback (rewards or penalties).
– It’s powerful for sequential decisions—think robotics, self-driving cars—but notoriously tricky to tune and often sample-inefficient. You end up with models that learned by, well, crashing a lot in simulations.
Other Approaches: Semi-supervised, Ensemble Methods
Let’s not overlook hybrid styles. Semi-supervised learning uses a mix of labeled and unlabeled data—practical when labels are expensive.
Ensembles (like Random Forests or Gradient Boosting) combine multiple models—weak ones—to forge stronger predictions.
These methods are pragmatic and jittery, sometimes overfitting until you coax them with clever regularization or validation tricks.
Real-World Examples: How Algorithms Animate AI Systems
Recommendation Engines That “Know You”
Ever notice how Netflix increasingly nails your taste? That’s often collaborative filtering techniques at play, using user–item matrices to infer preferences.
On the music side, Spotify’s Discover Weekly quietly blends content-based and collaborative approaches to serve tailored playlists. These systems evolve, slowly adapting as you drift between nostalgic ’90s rock and today’s lo-fi beats.
Fraud Detection: A High-Stakes Playground
Financial institutions deploy supervised learning—often ensemble models—to flag suspicious transactions. And yes, real stakes here: false negatives can cost millions; false positives frustrate customers. So algorithms must be accurate and explainable.
Layer in unsupervised anomaly detection, and suddenly your system sniffing out odd patterns becomes hybrid intelligence—guarding against evildoers and false alarms alike.
Autonomous Vehicles: Reinforcement and Vision Unite
Self-driving cars mash convolutional neural networks (CNNs) for perception with reinforcement learning or imitation learning for driving behavior. The synergy feels futuristic—but remember, real-world testing reveals edge cases (like unusual construction zones) that still trip up even the most sophisticated models.
Health Diagnostics: Caution + Insight
Medical imaging—like detecting tumors in scans—relies heavily on supervised deep learning models. They’re powerful, but must be audited: false diagnoses risk patient harm.
Explainability tools (like Grad-CAM or SHAP) help clinicians understand model reasoning, bridging the gap between black-box predictions and human trust. It’s a delicate balance: innovation and caution, side by side.
A Closer Look: Balancing Strengths and Limitations
Strengths of Various Algorithms
- Supervised learning: precise when you’ve got labeled data; direct feedback loop.
- Unsupervised learning: insightful for exploring data structure; useful when labels are scarce.
- Reinforcement learning: excels in sequential decision-making; great for complex simulation-based problems.
- Ensemble methods: enhance stability and predictive power by combining multiple weak learners.
Limitations and Challenges
- Data dependency: many algorithms demand large, clean datasets. Labeling is slow and expensive.
- Interpretability: complex models (like deep neural networks) often act like black boxes. That’s okay for personal recommendations, less so in high-stakes domains.
- Computation and tuning: Deep learning models require substantial compute and precise hyperparameter tuning, often through painstaking trial and error.
- Generalization gaps: models trained on historical data may flounder when faced with novel scenarios—hello, distribution shift.
“Even the most advanced algorithm is only as good as the data and objective it’s trained on. Reality throws curveballs; models must adapt.”
One risk is overconfidence—in ourselves or our models. Human oversight remains vital, especially when a misstep could have serious consequences. Always pair algorithms with checks, balances, and domain expertise.
When to Choose Which Algorithm
Step-by-Step Decision Framework
- Define your goal: Classification? Regression? Recommendation? Anomaly detection?
- Assess your data: Do you have labeled examples? Enough data? Clean enough?
- Consider complexity vs. interpretability: Deep neural nets versus simpler decision trees—trade-off between performance and clarity.
- Resource constraints: Budget for compute? Training time? Specialized hardware needed?
- Domain risks: Does the use case demand explainable decisions? Regulations matter.
Scenario Walkthroughs
- Startup with limited budget and supervised needs: Start with logistic regression or tree-based models; add ensemble later.
- Exploratory B2B platform: Use unsupervised clustering to uncover user segments before labeling or targeting.
- High-stakes enterprise deployment: Implement ensemble methods with explainability modules and audit trails to maintain trust and traceability.
In practice, teams iterate. You might prototype with simpler models, then scale complexity once you confirm signal and direction.
Emerging Trends and the Future of Machine Learning Algorithms
AutoML and Democratization
Automated Machine Learning (AutoML) tools now help non-experts build models. They automate feature selection, algorithm search, and hyperparameter tuning. While convenient, they still require human judgment to decide what’s valid and ethical.
Interpretability and AI Ethics
There’s growing pressure for models to explain themselves. Fields like healthcare and finance increasingly demand transparent reasoning. Explainable AI frameworks are becoming integrated into pipelines, not optional extras.
TinyML and Edge Inference
A significant share of inference is moving to devices—phones, sensors, IoT gadgets—where compute and power are limited. Algorithms optimized for efficiency (like quantized neural nets) are shifting intelligence closer to data sources, reducing latency and preserving privacy.
Hybrid Modeling: Bridging Symbolic and Statistical AI
Some researchers blend symbolic reasoning (rules-based logic) with statistical learning—trying to capture the best of both worlds: the rigor of logic with the adaptability of statistical models. It’s still experimental, but promising for fields needing both structure and flexibility.
Conclusion
Machine learning algorithms are indeed the brains behind AI—diverse, adaptive, and sometimes delightfully messy. From the straightforward logic of supervised learning to the free-form exploration of unsupervised methods, from the trial-and-error world of reinforcement learning to the protective synergy of ensembles—each has its place. What matters most is choosing the right algorithm for the right context, always anchored in data quality, interpretability, and domain expertise.
As innovation marches on, with trends like AutoML, TinyML, and hybrid approaches, it’s vital to keep humans in the loop—tuning, validating, and caring for the systems we build. That imperfect, unpredictable dance between algorithm and human judgment is where real progress happens.
FAQs
Q1: What makes supervised learning different from unsupervised learning?
Supervised learning uses labeled data to teach algorithms to predict outcomes, while unsupervised learning works with unlabeled data to identify patterns or groupings without predefined labels.
Q2: When is reinforcement learning most useful?
Reinforcement learning shines in environments where decisions unfold over time and feedback comes in rewards or penalties—common in robotics, gaming, and complex control systems.
Q3: Why are ensemble methods popular in the real world?
Ensembles combine multiple simpler models to improve overall accuracy and robustness, often outperforming any single model and reducing the risk of overfitting.
Q4: What’s the challenge with interpretability in deep learning?
Deep learning models can act like black boxes: they make decisions based on complex patterns without easily understandable reasoning. That makes them powerful yet sometimes hard to trust, especially in regulated domains.
Q5: How is TinyML changing the deployment of machine learning?
TinyML optimizes models to run on low-power, edge devices, bringing inference closer to the data source—cutting down latency, boosting privacy, and enabling smarter real-world applications.
Q6: Why is human oversight still essential in machine learning?
Algorithms depend on data and design choices. Mistakes, biases, or edge conditions can slip through. Human oversight ensures models stay aligned with real-world expectations, ethics, and safety.
(Approximate word count: 1,160 words)
